


Quantify the vibes with Stagehand: How good are LLMs at analyzing deeply nested, structured data?
Evaluating agents is still an unsolved problem.
Agents are designed to perform tasks, but assessing their performance involves many factors: did it do the right thing? How many “right” ways are there to do it? How many steps did it take? What kinds of tasks does it do well? What kinds of tasks does it do poorly?
Instead of trying to evaluate every aspect of an AI agent, we can focus on a simpler question: “Given a specific instruction like “click the button”, was the expected button clicked?”
This approach allows for more straightforward and rigorous evaluations. By concentrating on whether the AI can accurately translate a specific instruction into a precise action using tools like Playwright, we can better understand an LLM’s capabilities.

Stagehand: Break down agents into precise, natural language instructions
Stagehand (stagehand.dev) exposes “tools” for LLMs to control a browser, bridging the gap between fully agentic workflows and fully hardcoded Selenium/Playwright/Puppeteer. These tools are the following:
- Act: execute actions on a webpage with natural language using
act("click the button") - Observe: preview actions before they are executed with
observe("click the button")so you can cache actions or provide context to a higher level agent - Extract: extract structured data from webpages with
extract("the top news story")
By converting natural language instructions into precise web actions, Stagehand enables developers to describe a specific, precise action without having to worry about the tedium of writing cumbersome Selenium, Puppeteer, or Playwright code.
Stagehand composes a custom data structure that leverages the strengths of both the DOM and Accessibility (a11y) Tree to send to an LLM (example). The expected LLM output is a specific Playwright action that can be executed or cached for future usage. In doing so, the LLM can parse the entire website as text without the clutter of the raw DOM.
For example, act("click the jobs link") will analyze the DOM and a11y tree and output something like this:
For the times you want to write actual code yourself instead of relying on AI, Stagehand has full compatibility with Playwright, allowing you to have as fine-grained control as you want.
What makes Stagehand evaluations rigorous?
We have a set of evals that we use to test against regressions in our PRs. These evals are simple — take an action with Stagehand, and then check if the output (Playwright action or text) matches the expected output. We run the following sets of evals:
- Act: Go to a page, run an action like
"click the login button", and verify the resulting page URL contains/login. - Extract: Go to a page, extract data like
"the top news story", and then check if the extracted data matches the expected output. - Observe: Go to a page, plan an action like
"click the login button", and then check if the action preview has the intended interaction and DOM selector. - Combination: Chain
act(),observe(), andextract()together to test the models’ ability to handle more real-world tasks.
We have ~10 tests per category, and we run each eval 3 times per model to account for any website volatility. Many websites are cloned via Surge and hosted on GitHub Pages to remove website volatility and antibots where possible.
We tracked exact match rate, speed, cost, and error rates to provide a comprehensive evaluation of each model’s performance.
The results: Gemini takes the crown, and it’s not close
Which models are the most accurate?

Gemini 2.0 Flash takes the crown as the most “accurate” model — some other interesting takeaways:
- Llama 4 had pretty disappointing results, even with their Maverick model, which was supposed to be on par with the other frontier, flagship models
- Claude 3.7 Sonnet performed worse than its predecessor 3.5, and even worse was that GPT-4.5 was atrocious.
- Gemini 2.0 Flash-lite has surprisingly good performance for such a small model — it’s half the price of Gemini 2.0 Flash, which is already ridiculously cheap
Does a price premium equate to better performance?
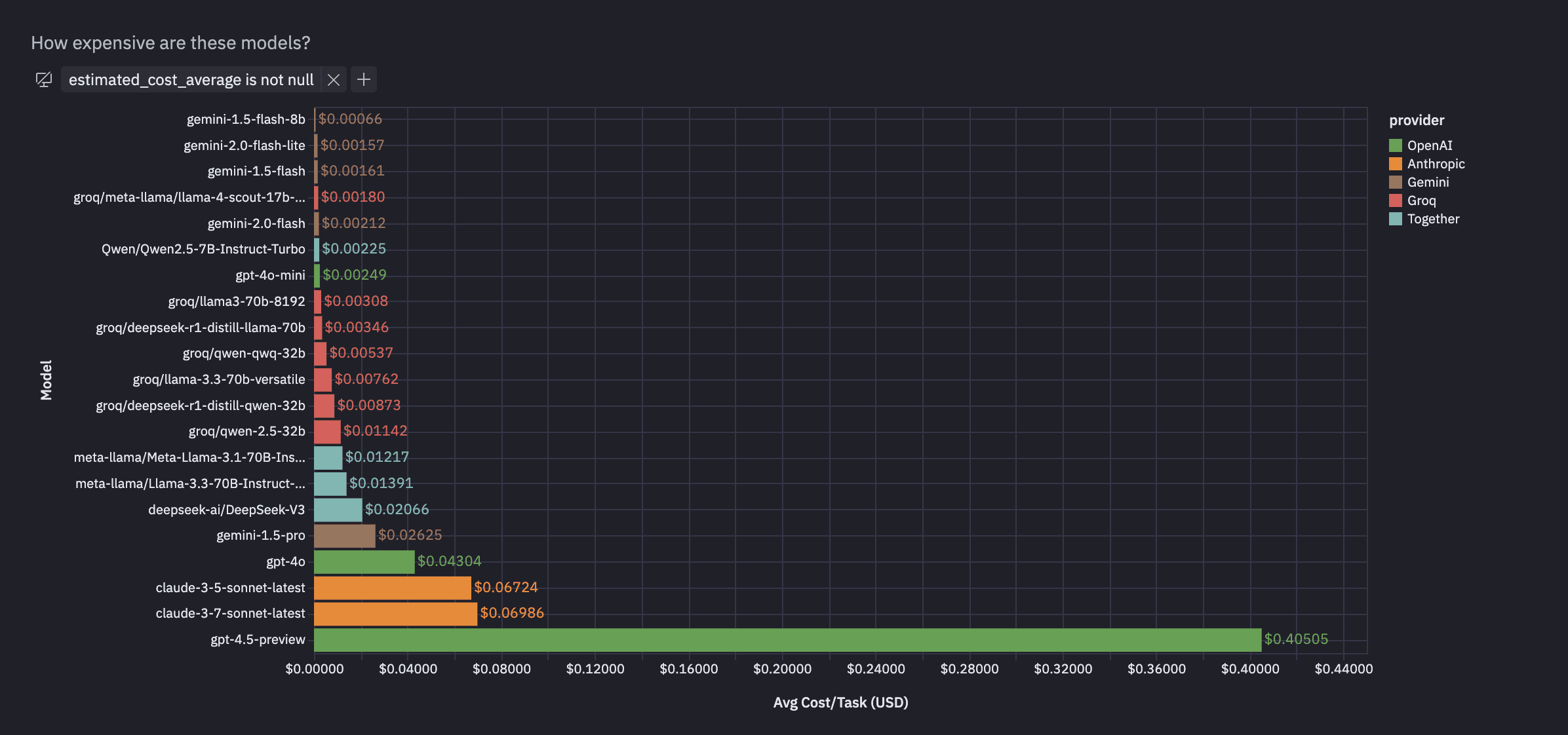
Adding price adds a whole new dimension — Gemini 2.0 Flash, the most accurate model, came in at about $.002/task — you could run each set FIVE TIMES for ONE CENT. The next best model, GPT-4o, offers slightly worse performance for 20x the cost, and that’s still cheaper than Claude!
GPT-4.5 is, again, horrendously expensive and inaccurate.
What about how fast the models are?
We measured average LLM inference time per task, and once again, Gemini is ridiculously good.
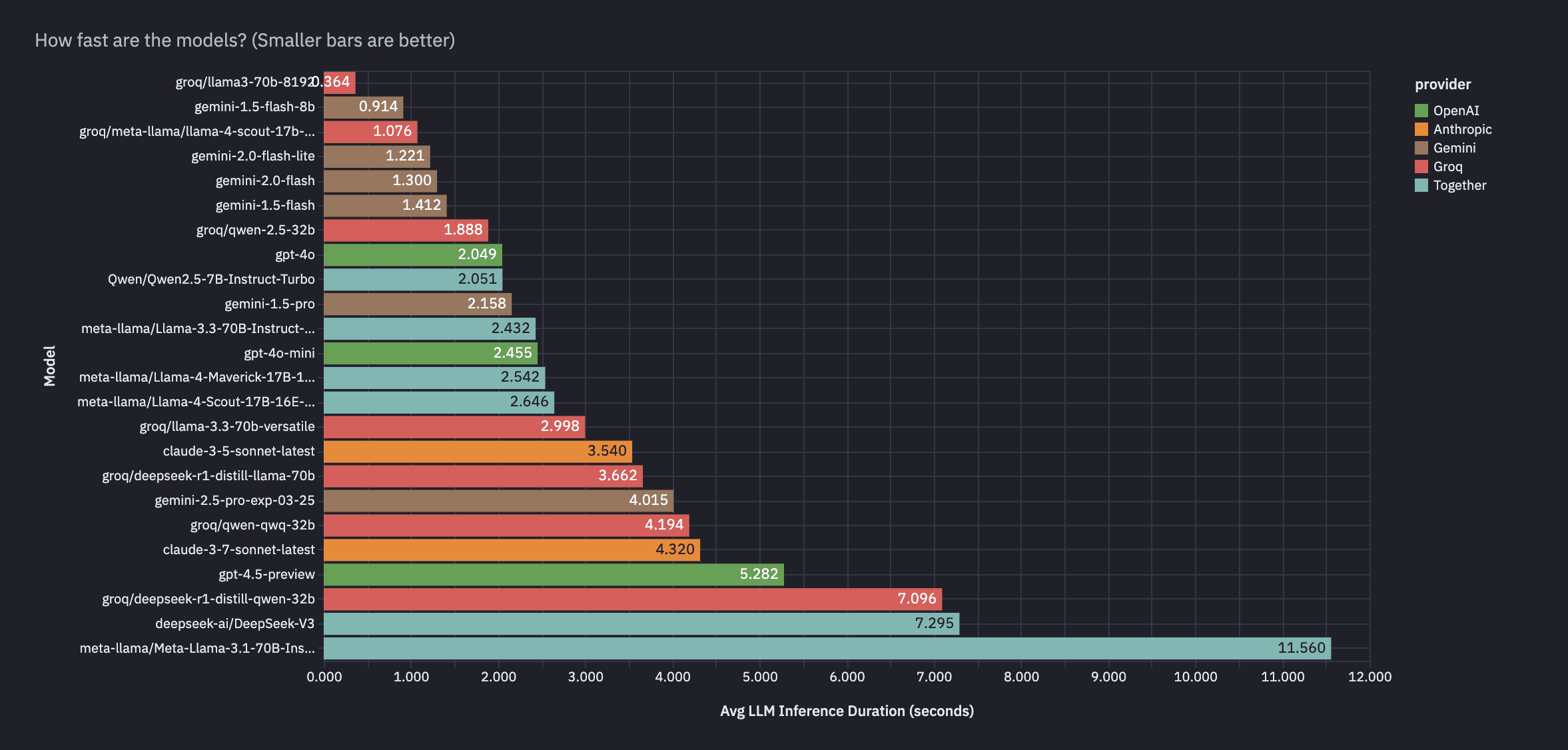
Groq’s hosted Lllama 3 70B model takes the cake for the fastest model, but it’s far from the most accurate. Gemini is again among the cheapest and most accurate models, and it’s also top 5 in latency, ahead of its frontier counterparts by OpenAI and Anthropic.
Overall, Gemini 2.0 Flash is the most accurate model AND among the fastest and cheapest.
Break down by act, extract, and observe (full Analysis on Hex)
We made these charts on Hex, and the full analysis can be found here, including links to Braintrust runs with chat traces per eval.
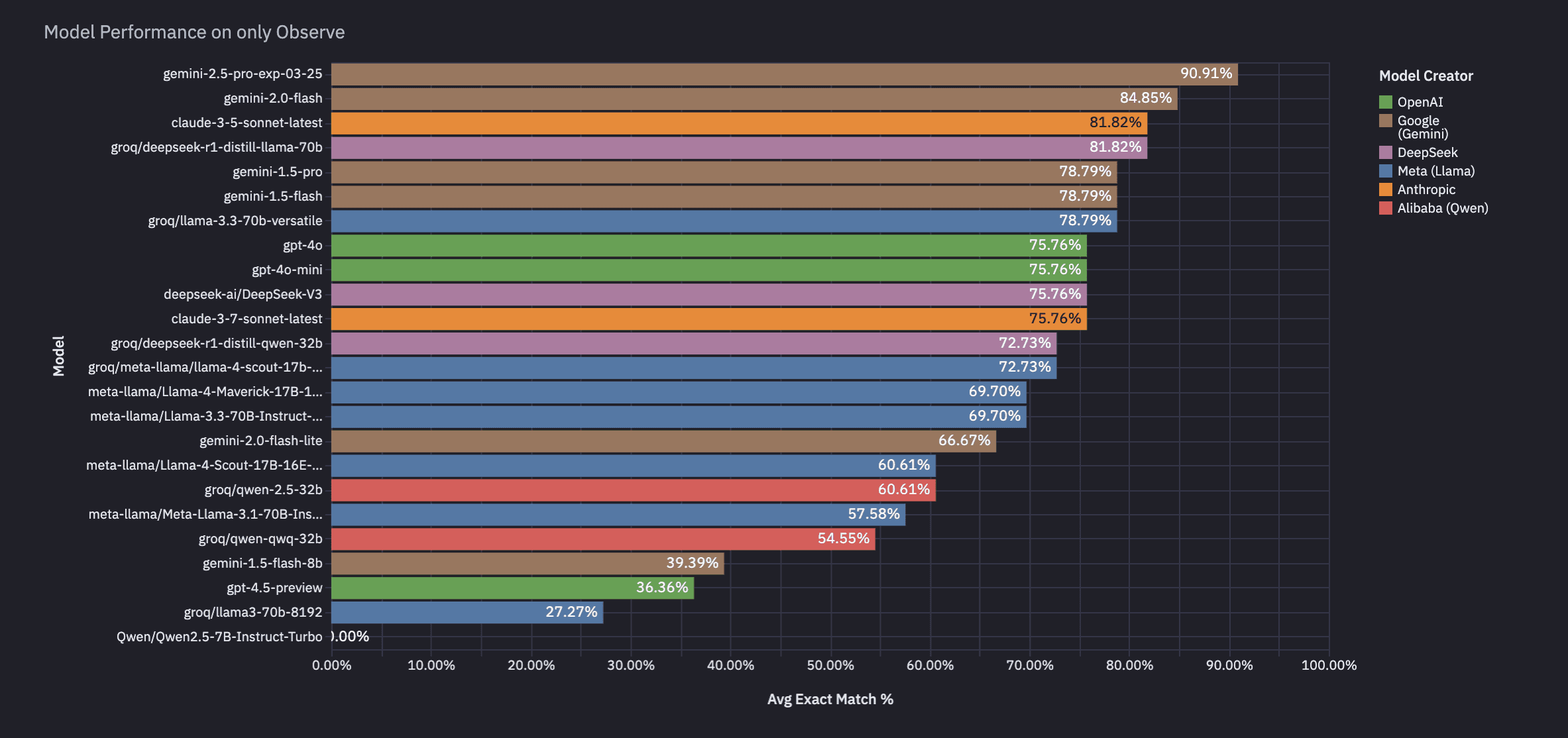
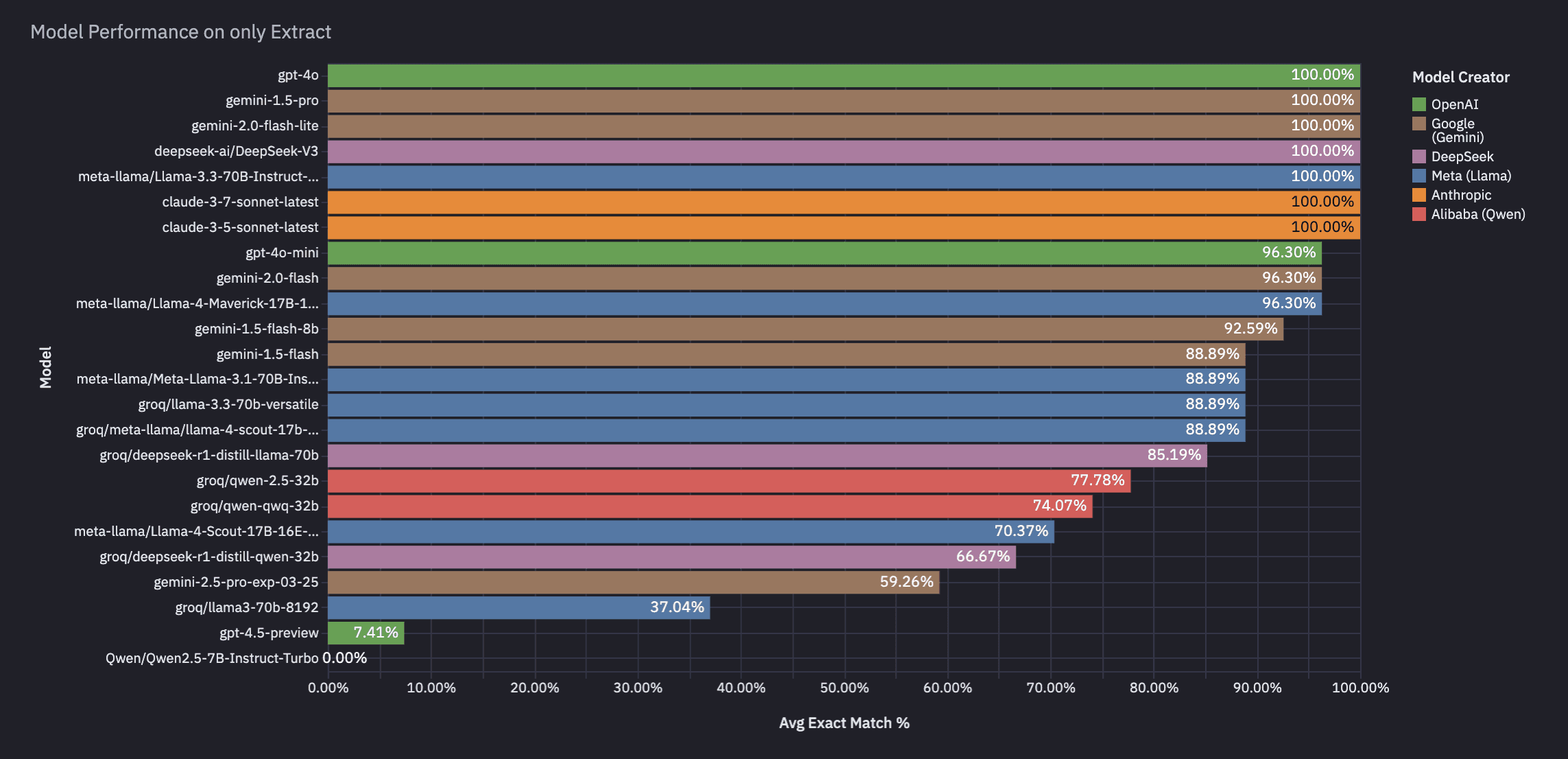
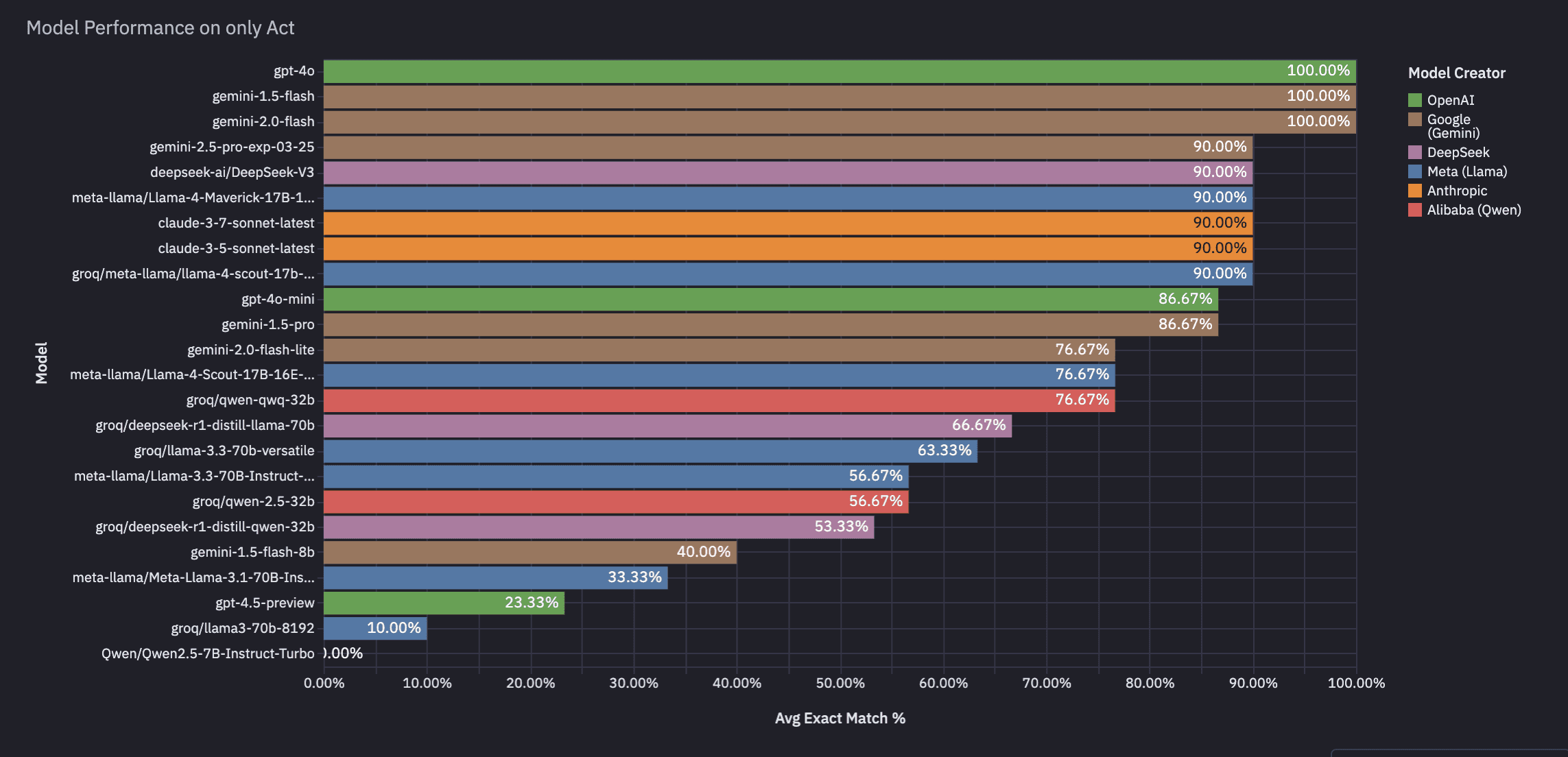
Conclusion
- Gemini is unreasonably good — the cheapest AND most accurate, and among the fastest models on the market.
- GPT-4o and Claude 3.5 Sonnet were pretty good, but not worth the 20-30x price premium over Gemini.
- Newer models like Claude 3.7 Sonnet and especially GPT-4.5 seem more “creative” and not ideal for doing exactly what you want to do.
- Get Started with Stagehand: We’ve open-sourced Stagehand to help you get started with AI-powered web automation. Get started with Stagehand at stagehand.dev.


