

The variety of models capable of interacting with the internet to automate real tasks continues to expand. Today, Microsoft is announcing Fara-7B, a small computer-use vision language model (VLM) that achieves new state-of-the-art results for its size.
Training and evaluating browser-based agents at scale requires reliable access to real websites, high concurrency, and consistent execution environments. Meeting these requirements directly impacts both reinforcement learning workflows and the accuracy of model evaluation.
That is why Microsoft has exclusively partnered with Browserbase to train, evaluate, and deploy their next generation of open-source computer-use models. As Corby Rosset, Principal AI Researcher at Microsoft, put it:
“Without Browserbase, it would not have been possible to seamlessly train our model with reliable access to real-world websites.”
Building upon our existing work with Deepmind, we were able to integrate, host, and independently evaluate Fara-7B on Browserbase within a week to provide fair and reliable benchmarking
The results were surprising… a good surprise.
Introducing Fara-7B - a small but mighty model
Fara-7B delivers unmatched speed and cost efficiency for its size, with meaningful real-world capability. When benchmarked on the publicly available 595-task WebVoyager dataset updated in collaboration with Microsoft and using human-verified scoring, Fara-7B significantly outperformed similar open-source models.
Here are the results (pass@1 with up to 5 retries):
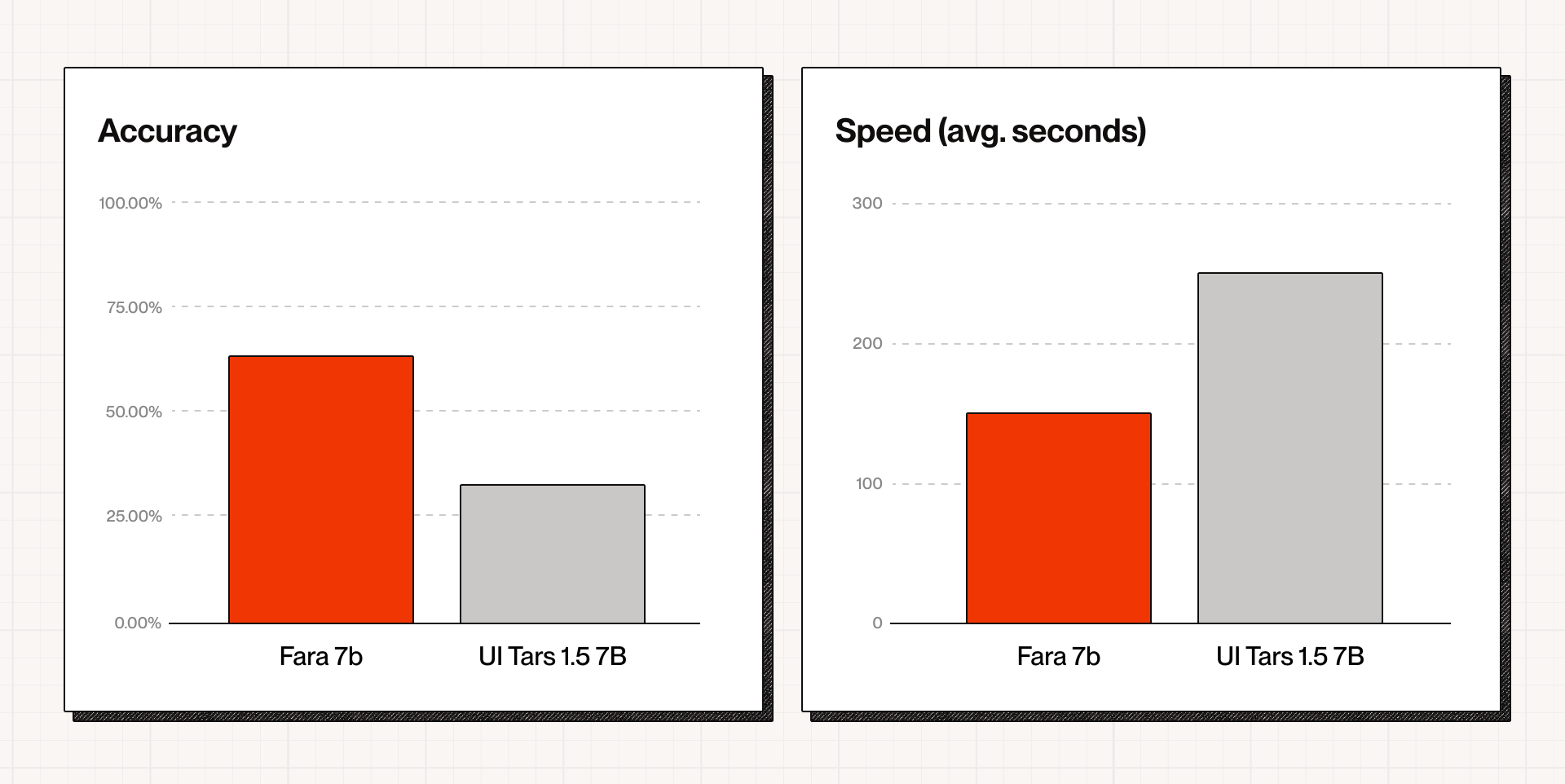
Small computer-use models like Fara-7B meaningfully change the unit economics of browser agents. Sub-second inference and dramatically lower compute costs enable running multiple agents in parallel, unlocking workflows that simply are not feasible with large proprietary models.
Browserbase evaluation criteria
To ensure fairness, we evaluated 7B-size models only, using Microsoft’s updated version of Web Voyager.
We used pass@1 with up to 5 retries, reflecting real-world deployment patterns for small self-hosted models. All evaluations ran on Browserbase’s deterministic browser infrastructure, ensuring consistent environments without variability from rate limits, random states, or anti-bot checks. Every task was human-verified, with evaluators reviewing screenshots, full web trajectories, and the final task state to confirm completion. We measured accuracy, cost, and speed across all 595 tasks.
We will continue expanding this evaluation approach, including re-running Gemini, OpenAI CUA, and other frontier models using the same retry-friendly methodology to make comparisons fully consistent.
Why independent evaluation matters
Evaluation of computer-use models across the industry is fundamentally inconsistent, which is why UI-Tars 1.5-7B performed far worse than its published numbers.
Here is what we consistently see:
- LLM judging is unreliable. Different evaluators use different judge models, thresholds, prompts, or exclude failures.
- Websites change. Benchmarks using live websites break, get redesigned, rate-limit, or show entirely different flows.
- Strictness varies widely. One judge model passes an action, another flags it as incorrect.
When we evaluated UI-Tars, we found that many tasks reported as “successful” were incomplete or incorrectly executed, including cases where an LLM judge passed trajectories that a human evaluator would not consider correct.
This is exactly the motivation behind the Stagehand Evals CLI and and our broader benchmarking work, which allows you to run real models on real websites using reliable browser infrastructure that eliminates site-level noise, provides fully observable sessions with screenshots and logs, and incorporates human verification to catch what automated judges miss.
Standards produce reliable computer-use model evaluation, and reliability builds trust. That trust is why leading research teams like Microsoft and DeepMind partner with us to benchmark their models and make results reproducible for the community.
Open source and available today
Fara-7B is available today, with full open weights on HuggingFace and Azure AI Foundry, and Stagehand has built-in support for it out of the box. You can deploy it via:
- Azure Foundry (hosted directly by Microsoft)
- Fireworks, which made running both models effortless and supported fair inference comparisons
You can try it out on Stagehand by running:
Huge thanks to the Fireworks team for fast hosting and model support.
Calling all researchers
We are excited about the next generation of small, fast, open models, and equally committed to building the infrastructure required to evaluate them correctly.
This collaboration highlights a broader shift in how computer-use models are being built. The most successful approaches tend to share several traits: training on the real web instead of synthetic environments, grounding models through interaction and feedback, optimizing for practical deployment rather than benchmark-only performance, and maintaining transparency through shared trajectories and verification.
If you are training or fine-tuning a computer-use model, reach out.
We would love to help evaluate your model, validate it with human verification, and share feedback that helps move the ecosystem forward.



