Product and pricing data
Catalogs, prices, inventory, and specs from ecommerce and B2B storefronts.
The web was not built for agents. Browserbase runs real cloud browsers that extract structured data from any website: Verified access, JavaScript rendering, and AI parsing turn messy pages into clean JSON, ready for your pipeline. Built on infrastructure that runs 35m+ browser sessions a month.

The Problem
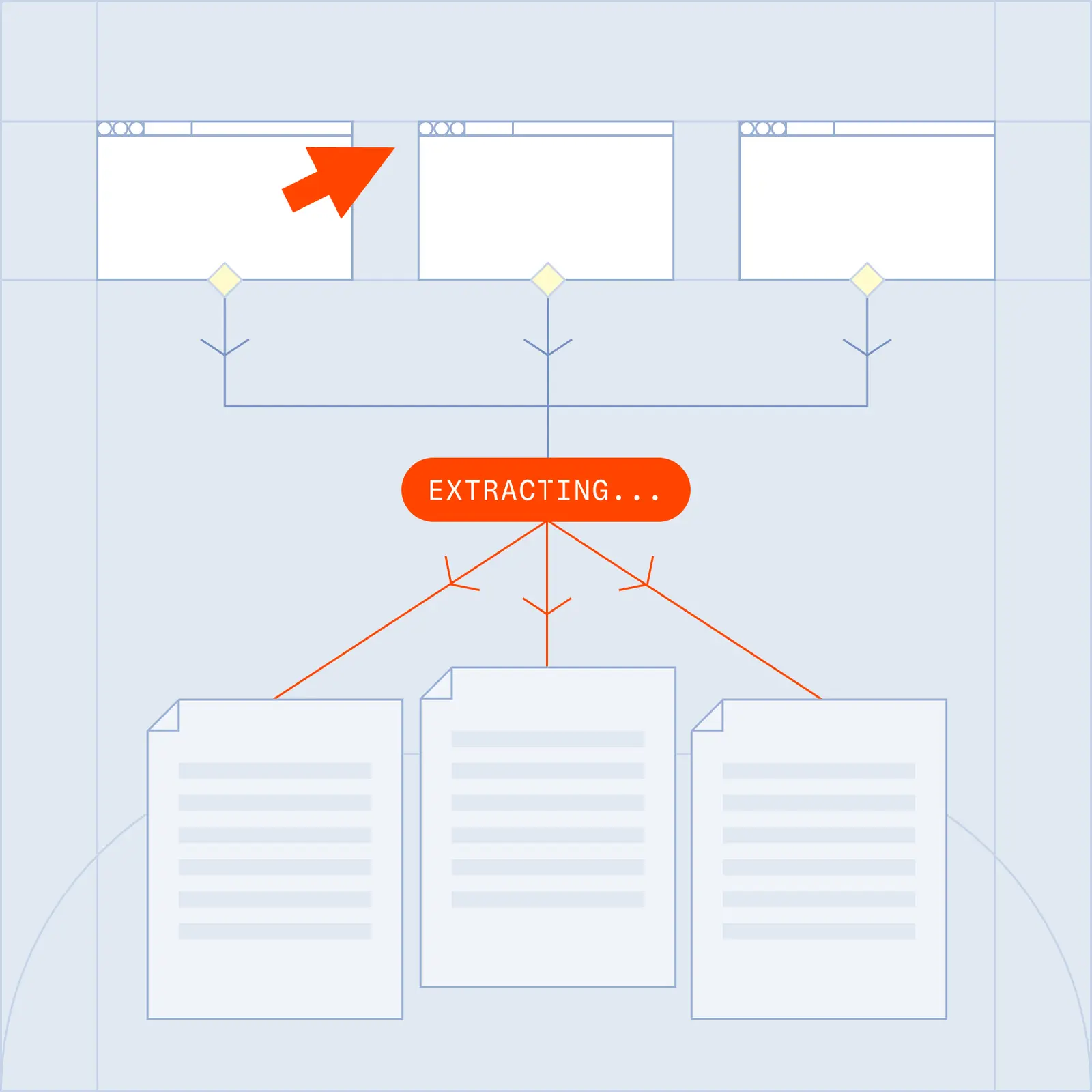
The Solution
Catalogs, prices, inventory, and specs from ecommerce and B2B storefronts.
Firmographics, employee counts, leadership, and contact details from public profiles.
Filings, indices, market signals, and alternative data from public portals.
Web data extraction is the process of pulling structured information from websites and turning it into a usable format like JSON, CSV, or a database row. It powers competitive intelligence, lead generation, price monitoring, market research, and AI training pipelines. Modern web data extraction relies on real browsers, because most sites render content in JavaScript and were never built for automated access.
Traditional tools rely on HTTP requests and hard-coded selectors that break when sites change. Browserbase runs real Chrome browsers in the cloud, so every page renders exactly like it does for a human user. Pair that with Stagehand for AI-driven parsing and you get extraction that adapts to layout changes, handles dynamic content, and avoids the brittle maintenance cycle of legacy scrapers.
Yes. Browserbase includes Verified access, residential proxies, and managed CAPTCHA solving for common challenge types. Real browser fingerprints and isolated sessions let extraction jobs reach pages that turn away traditional scrapers. Agent Identity adds Web Bot Auth signed requests, so sites can verify your agent instead of guessing.
The web was not built for agents. Browserbase runs real cloud browsers that extract structured data from any website: Verified access, JavaScript rendering, and AI parsing turn messy pages into clean JSON, ready for your pipeline. Built on infrastructure that runs 35m+ browser sessions a month.
The Problem
The Solution
Catalogs, prices, inventory, and specs from ecommerce and B2B storefronts.
Firmographics, employee counts, leadership, and contact details from public profiles.
Filings, indices, market signals, and alternative data from public portals.
Web data extraction is the process of pulling structured information from websites and turning it into a usable format like JSON, CSV, or a database row. It powers competitive intelligence, lead generation, price monitoring, market research, and AI training pipelines. Modern web data extraction relies on real browsers, because most sites render content in JavaScript and were never built for automated access.
Traditional tools rely on HTTP requests and hard-coded selectors that break when sites change. Browserbase runs real Chrome browsers in the cloud, so every page renders exactly like it does for a human user. Pair that with Stagehand for AI-driven parsing and you get extraction that adapts to layout changes, handles dynamic content, and avoids the brittle maintenance cycle of legacy scrapers.
Yes. Browserbase includes Verified access, residential proxies, and managed CAPTCHA solving for common challenge types. Real browser fingerprints and isolated sessions let extraction jobs reach pages that turn away traditional scrapers. Agent Identity adds Web Bot Auth signed requests, so sites can verify your agent instead of guessing.
Articles, listings, reviews, and ratings from any public-facing website.
Use Stagehand, Browserbase’s AI browser automation framework. You describe the data you want in plain English and pass a schema, and the Stagehand SDK returns typed, structured output. When a site changes, the AI adapts. No selector maintenance, no broken pipelines.
Yes. Browserbase Contexts let you persist cookies, localStorage, and session state across runs. Sign in once, save the context, and reuse it on every extraction job without triggering MFA or login walls.
Run sessions in parallel. Browserbase scales to thousands of concurrent browser sessions on demand, so a one-page extraction script becomes a fleet-wide data pipeline without infrastructure work on your end.
Whatever you need. The Stagehand SDK returns typed objects you can serialize to JSON, CSV, or write directly to your warehouse. Combine that with Browserbase’s Fetch API, downloads, and screenshots, and you can capture text, structured records, files, and visual snapshots from the same run.
Articles, listings, reviews, and ratings from any public-facing website.
Use Stagehand, Browserbase’s AI browser automation framework. You describe the data you want in plain English and pass a schema, and the Stagehand SDK returns typed, structured output. When a site changes, the AI adapts. No selector maintenance, no broken pipelines.
Yes. Browserbase Contexts let you persist cookies, localStorage, and session state across runs. Sign in once, save the context, and reuse it on every extraction job without triggering MFA or login walls.
Run sessions in parallel. Browserbase scales to thousands of concurrent browser sessions on demand, so a one-page extraction script becomes a fleet-wide data pipeline without infrastructure work on your end.
Whatever you need. The Stagehand SDK returns typed objects you can serialize to JSON, CSV, or write directly to your warehouse. Combine that with Browserbase’s Fetch API, downloads, and screenshots, and you can capture text, structured records, files, and visual snapshots from the same run.